

Many of you are familiar with the Birthday Paradox. If you want to read more about it you can find a good article here. Basically, it says that in a room of 23 people, there is a 50% chance that at least two people share a birthday. And if you increase that number to 75 people, the chances go up to 99.9%. I wanted to explore this a little more and rather than doing the math (boring!), I decided to do a Monte Carlo simulation, run it a bunch of times, and plot the results.
Like most of my Monte Carlo simulations, this will be in the C programming language. I like C because it is usually much faster than interpreted languages like Python and Java. With these simulations, I like to start with just one iteration or version and after that is working, expand it to other versions. In this case, we will start with a version where there are 23 people in the room. In that version, we will do 1000 iterations and in each iteration we assign random birthdays to the 23 people and then check to see if there were any matches. After we have this working, we expand it by wrapping the entire thing in another for loop that iterates through the number of people in the room from 2 to 100. Why stop at 100? Because it’s a nice round number and at that point, the chance of a birthday match has been at 100% for awhile so it doesn’t really achieve anything to continue.
#include <stdio.h> // print
#include <stdlib.h> <span data-mce-type="bookmark" id="mce_SELREST_start" data-mce-style="overflow:hidden;line-height:0" style="overflow:hidden;line-height:0" ></span> // rand
#include <time.h> // time
// This program will determine the percentage of times that two or more people share a birthday
// It will iterate from 2 people to 'maxNumPeople' and in each version it will do 'numSimulations' simulations
int main()
{
int numPeople; // Number of people in this version
int maxNumPeople = 100; // Maximum number of people to test with. Must be less than 100
int simNum; // Simulation number
long numSimulations = 1000000; // Number of simulations to try in this version
long numMatches; // Keeps track of number of matches in this version
int birthdays[100];
int i, j; // Incrementers fin for loop
int isMatch; // Flag for later
// Seed RNG with time to get unique results each time
srand(time(NULL));
// Iterate over the number of people in this version
for(numPeople=2; numPeople<maxNumPeople; numPeople++)
{
// Reset the number of matchs for this version
numMatches = 0;
// Iterate the number of simulations in this version
for(simNum = 0; simNum<numSimulations; simNum++)
{
for(i=0; i<numPeople; i++)
{
// Give each bday a value, in this case a day from 1 to 365 inclusive
// rand()%365 returns from 0 to 364 so we add 1 to it
// We could just as easily leave the 1 off and it would still work, but doesn't hurt
birthdays[i] = 1 + rand()%365;
}
// Reset the isMatch flag
isMatch=0;
// Determine if there is a match
// Note that this is a very inefficent way to do compare
for(i=0; i<numPeople-1; i++)
{
for(j=i+1; j<span data-mce-type="bookmark" id="mce_SELREST_start" data-mce-style="overflow:hidden;line-height:0" style="overflow:hidden;line-height:0" ></span><numPeople; j++)
{
// Compare i and j birthdays
if(birthdays[i] == birthdays[j])
{
// If they match, then set flag and break
isMatch=1;
break;
}
}
// This flag is to break out of the outer for loop if a mathc is already found
if(isMatch==1)
{
break;
}
}
// If the match flag was set, increment the number of matches
if(isMatch==1)
numMatches++;
}
// Print out the numPeople in this version and the percentage of times there wa a match
printf("%d, %f \n", numPeople, 100.0*numMatches/numSimulations);
}
return 0;
}
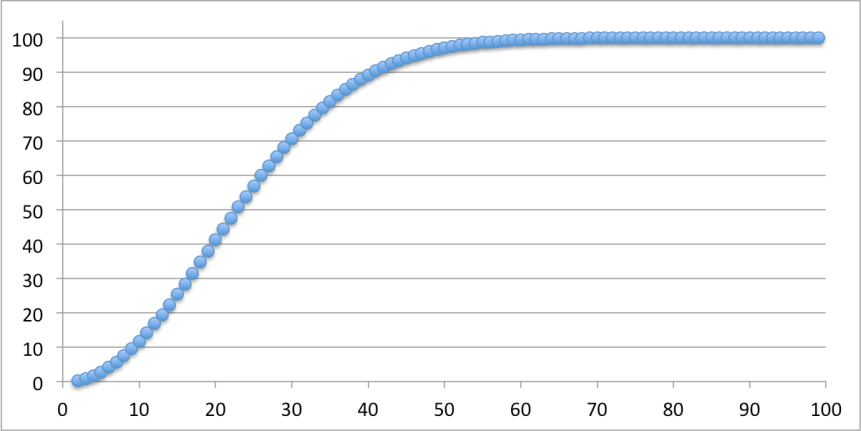
After you run the code, you get a text output that can be used to create this graph. This data was done with 1 million iterations with each number of people. At 23 people, the chances are just over 50%, at 57 people it goes up to 99%, and at 70 people it hits 99.9%. This doesn’t match the mathematical model perfectly, but it’s pretty darn close.
One thing to note is the method of checking to see if there are any matches. The method above is not necessarily super efficient but is quick to write. And since the whole thing runs in just over two minutes on a slow computer, there’s not a ton of value to super optimizing it. But one optimization I did do is with the break statements. Whenever a match is found, a flag is set and then that inner for loop is broken out of and then the flag is used to break out of the outer loop. This is necessary because C does not have the ability to break out of two loops without using a goto statement. You may think that this doesn’t save very much time, but it actually saves a ton of time. Below is the data up to one million iterations and you can see that having those breaks reduces the time required by 75%. These times are from a 2013 (4 years old) laptop running a 2.4GHz Intel Core i5.
| Iterations | No Break | With Break |
| 100 | 0.3s | 0.2s |
| 1000 | 0.8s | 0.3s |
| 10000 | 6.2s | 1.5s |
| 100000 | 61s | 14s |
| 1000000 | 600s | 143s |
In the future, I’d like to do the same test in the future but use a bubble sort before finding matches so that I can sort out how often there are two separate matches, etc.
Any questions? Feel free to comment below!
